需要了解的AI术语,紧跟工业DX的关键
随着深度学习技术取得巨大进步,逐步推进AI(人工智能)技术的实用化。大家都期盼AI技术实用化能解决各种社会问题。
在工业领域可利用IoT或5G通讯技术实时收集现场的详细数据。运用AI技术,催生出可快速适应情况变化的新商业模式。数字化转型(DX)的趋势也将愈演愈烈。
本次技术专栏将在纵览、概述AI(人工智能)相关的周边技术基础上,结合工业领域的运用图示和各步骤,介绍该做怎样的准备。
AI(人工智能)与深度学习有何种关系? 纵览周边技术
想必在当下提到AI,很多人会首先想到深度学习。但大家真的理解AI与深度学习的关系吗?
先来纵观一下AI相关的周边技术关系(图1)。
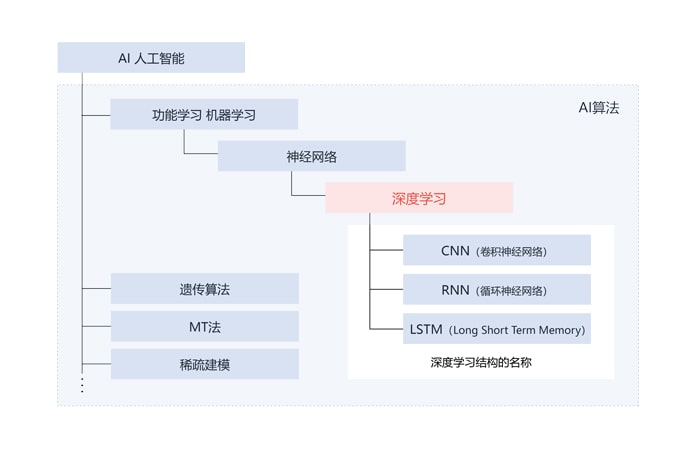 图1:AI(人工智能)相关的周边技术及其关系
图1:AI(人工智能)相关的周边技术及其关系
什么是深度学习
所谓深度学习可以分类为AI算法中机器学习的一种,即神经网络的一种进阶版本。
什么是机器学习
机器学习就是在不进行人工编程,而是通过给予机器(计算机)数据,让机器自行学习判断的算法。这种方法用到的结构模仿了人类的神经回路,也就是神经网络(图2)。
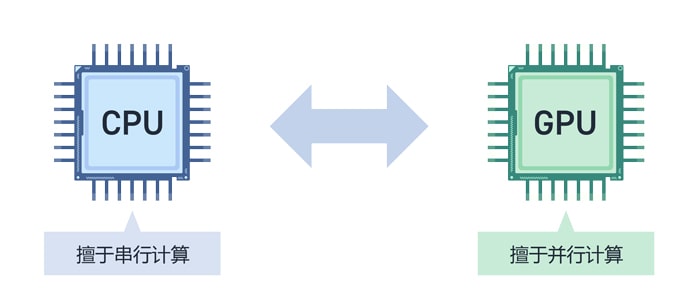 图2:利用神经网络识别图像的图示
图2:利用神经网络识别图像的图示
深度地将神经网络的中间层划分为多级结构(深度神经网络)的学习算法就是深度学习(图3)。
 图3:神经网络和深度学习的结构
图3:神经网络和深度学习的结构
深度学习还可以根据层的结构,进一步分为擅于识别图像的CNN(卷积神经网络),擅于识别声音、视频等时序数据的RNN(循环神经网络)。
从广义来看,AI除机器学习外,还有遗传算法、马田系统、稀疏建模等算法,这些算法各有不同的适用对象与场合。
但在识别图像、声音方面硕果累累,正掀起第3次AI热潮的还是分属于机器学习的深度学习,这是如今前景最受期待的算法。
AI/深度学习需要使用GPU的理由
构建神经网络的神经元计算可以同时并行计算。这种情况下,使用核心数较多的GPU(图形处理器),可通过并行处理大量计算来实现高速化。
GPU原本进步的目的是为了提高在计算机上显示3D图形的速度。例如要在3D图形中让物体旋转,就必须计算物体各个描绘点的旋转。但这种情况下,分别并行计算处理各描绘点会比按顺序计算每个描绘点更快速。
GPU为并行计算这类3D图形,集成了成百上千的微型核心。这就是也同样适合深度学习计算的原因。
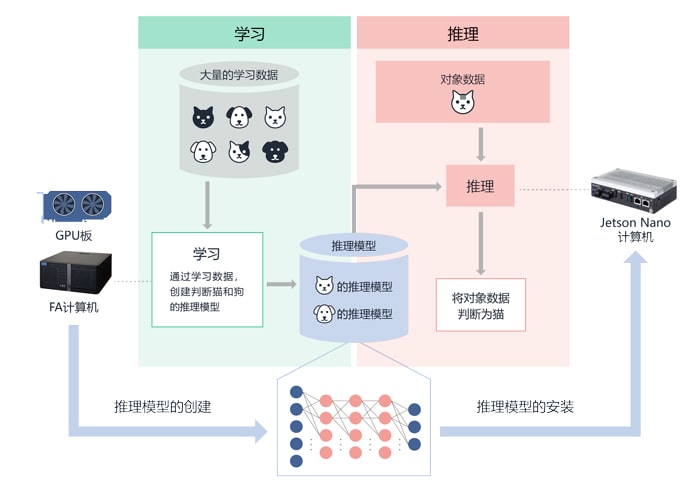 图4:CPU和GPU
图4:CPU和GPU
实际运用图示和各步骤上的思考
将对象数据(猫的图像)分发给通过深度学习进行学习的神经网络,就可得到识别的判断结果(“该图像是猫”)。将该执行称为推理,完成学习的神经网络称为推理模型。反过来说,生成这种推理模型的作业就是学习。
学习需要大量数据与计算,但执行推理时对计算能力的要求会低于学习时。因此,一般都是用高性能计算机进行学习,将得到的推理模型部署到现场的计算机(边缘AI计算机)上,投入到实际应用中(图5)。
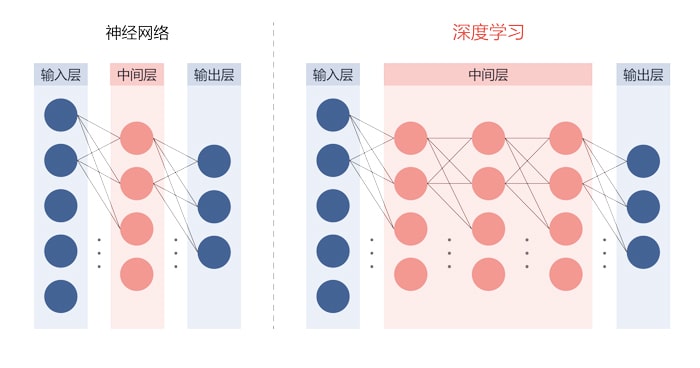 图5:AI应用程序的运用图示
图5:AI应用程序的运用图示
工业领域中的推理模型生成(学习环境)
深度学习必须有配备GPU板的高性能计算机(HPC)环境。如果在临时的学习环境下,也可使用消费级的PC或云环境,但如果用于需持续使用的工业用途,则会面临产品的可靠性及供给期限的问题。
理想环境应该是有可以安装高性能GPU板的扩展插槽、大容量电源、或能发挥GPU板性能的高性能CPU,且产品供给及保修服务时间长的工业用计算机。
CONTEC有可选择适用高端GPU板扩展插槽、大容量1000 W电源、大容量RAID存储器的高性能FA计算机。
在工业领域中部署推理模型(执行环境)
NVIDIA公司的Jetson的开发者套件是有名的推理执行环境。Jetson的开发者套件是面向阶段性开发AI应用程序的开发者及教育方向的工具,所以在工业领域会面临设备耐环境性、供给期限、可设置性、I/O接口不足的问题。
CONTEC可提供搭载NVIDIA® Jetson Nano™ / Xavier NX™ 模块的执行推理计算机。该计算机搭载有工业用的Gigabit LAN、HDMI、2x USB,通用I/O、RTC(实时/日历钟),可进行灵活设置,并具备耐环境性。

配备NVIDIA® Jetson Nano™ 工业用边缘AI计算机

配备NVIDIA® Jetson Xavier NX™ 工业用边缘AI计算机
如何看AI/深度学习的性能差异?
通过深度学习生成和执行推理模型其实是并行执行乘积累加计算,所以性能与GPU核心的乘积累加计算能力及核心数有关。
乘积累加计算能力因计算精度的不同而异(INT8 / FP16 / FP32)
在核心内的乘积累加计算精度方面,INT8是指8位整数计算,FP16、FP32是指16位及32位的半精度浮动小数点计算。INT8项目中1TOPS表示1秒内可进行1兆次8位整数计算。
在生成推理模型时(学习步骤),计算精度十分重要,所以应当重视半精度浮动小数点计算能力(FP16 / FP32)。另一方面,在部署推理模型时(执行步骤),执行速度优先于计算精度,所以要重视整数计算能力(INT8)。
尽管如此,但结果也会因深度学习的结构、数据、除GPU外的系统不同而异。只凭该数值是无法比较深度学习的性能。
基准测试 MLPerf / ResNet50时
MLPerf是为在同一指标下比较性能而推出的行业标准基准测试。利用多家企业、大学和研究机构合作制定的机器学习基准测试,可以测算同一模型的学习时间、推理时间,从而评估性能。结果会在MLPerf的网站上公开。
在己方环境下如果条件齐备,也可以用特定的模型的学习、推理时间进行比较。ResNet50是用于图像识别的50层深度学习模型,也是MLPerf的指标项目之一,广泛用于比较不同系统的性能。
CONTEC面向AI/深度学习的平台
下表为CONTEC面向AI/深度学习的产品一览。作为DX系列推广的推理模型部署(执行环境、边缘AI计算机)等专门针对AI的产品。另外还有为生成推理模型(学习环境)而准备的高性能FA计算机VPC系列。VPC系列还有出厂时安装GPU板的安装服务(有偿)。
相关链接
查看所有文章