AIにおけるディープラーニングとは?産業DXに乗り遅れないための勘所
ディープラーニング(深層学習)技術の大きな進歩に伴い、AI(人工知能)技術の実用化に向けた研究開発が進んでいます。AI技術の実用化がさまざまな社会的問題の解決につながるとして、期待が集まっているのです。
産業分野ではIoTや5G通信の技術によりフィールド(現場)の詳細データをリアルタイムに収集。AI技術により、状況変化にすばやく適応可能な新たなビジネスモデルへと変革。まさにデジタルトランスフォーメーション(DX)の機運が高まっています。
今回の技術コラムでは、AI(人工知能)に関連する周辺技術を俯瞰的に整理、概説した上で、産業分野における運用イメージや各プロセスで何を用意したらよいかを説明します。
目次
AI(人工知能)とディープラーニングの関係
今日では、AI といえばディープラーニングと考える人が多いでしょう。しかし、AIとディープラーニングの関係性を理解しているでしょうか。
まずは、AI と関連する周辺技術の関係を俯瞰して整理してみます(図1)。
 図1:AI(人工知能)に関連する周辺技術とその関係
図1:AI(人工知能)に関連する周辺技術とその関係
AIとは
AIとはArtificial Intelligenceの略で、日本語では人工知能のことです。AIの定義自体は研究者によってまちまちですが、簡単な説明としては『人間の知能を計算機(コンピュータ)で実現しようとする』ということです。コンピュータで実現できるのは、人間の多様で汎用的な知能の一部にすぎませんが、画像認識や、自然言語処理、多くのデータから解を得るといった解析能力は、それまで人間でしかできなかったことを自動化することに役立ちます。
ディープラーニングとは
ディープラーニングとは、AIアルゴリズムの中のマシンラーニング(機械学習)の一手法であるニューラルネットワークの一つの進化系に分類できます。
マシンラーニングとは
マシンラーニングとは、人間がプログラミングせずにマシン(コンピュータ)にデータを与えることによって学習・判断させるためのアルゴリズムです。そのための手法に人間の神経回路を模した構造を用いるのがニューラルネットワークです(図2)。
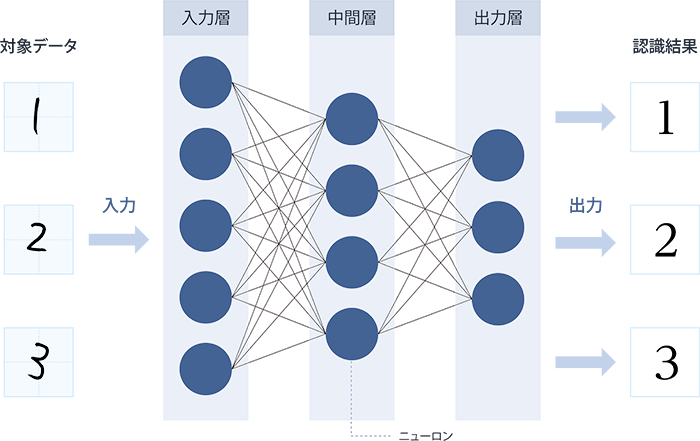 図2:ニューラルネットワークによる画像認識のイメージ
図2:ニューラルネットワークによる画像認識のイメージ
ニューラルネットワークの中間層を深く(deep)多段にした構造(ディープニューラルネットワーク)の学習アルゴリズムがディープラーニングという関係です(図3)。
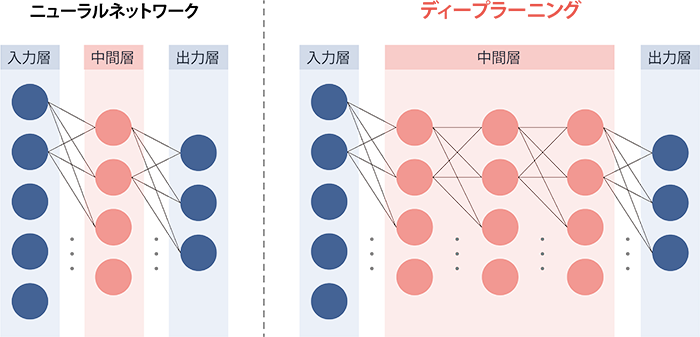 図3:ニューラルネットワークとディープラーニングの構造
図3:ニューラルネットワークとディープラーニングの構造
ディープラーニングの手法
ディープラーニングは、さらに層の構造の形によって、画像認識が得意なCNN(畳み込みニューラルネットワーク)、音声や動画などの時系列データ認識が得意なRNN(再起型ニューラルネットワーク)といった手法に分かれます。
広く見れば、AIにはマシンラーニングの他にも遺伝的アルゴリズムやMT法、スパースモデリングといったアルゴリズムもあり、適用の対象によってはこれらのアルゴリズムを用いた方が適切な場合もあります。
しかしながら、画像認識や音声認識の分野で特に大きな成果を上げ、現在の第3次AIブームを起こしたのは、やはりマシンラーニングに属するディープラーニングであり、現在最も発展が期待されているアルゴリズムです。
CNN(畳み込みニューラルネットワーク)
CNNとは、「Convolutional Neural Network」の略で、日本語では「畳み込みニューラルネットワーク」と呼ばれます。「畳み込み層」と「プーリング層」を持つネットワークで、入力のデータ全体を一度に処理するのではなく、部分ごとに「畳み込み層」で特徴を抽出、部分の位置による影響を抑える機能を持つ「プーリング層」を通した後、全結合で全体の判断を行う構造です。特に、画像認識の分野で有効なニューラルネットワークの構造です(図4)。
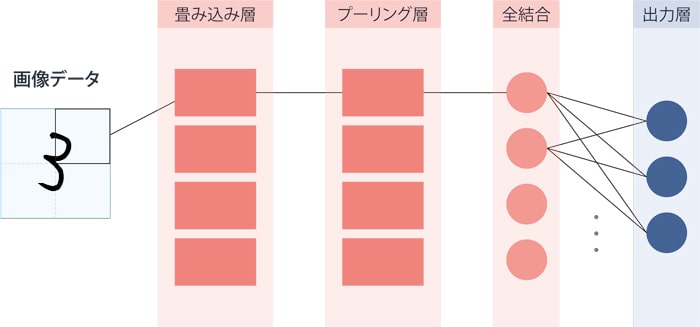 図4:CNN(畳み込みニューラルネットワーク)
図4:CNN(畳み込みニューラルネットワーク)
RNN(再起型ニューラルネットワーク)
RNNとは、「Recurrent Neural Network」の略で、日本語では「再帰型ニューラルネットワーク」と呼ばれます。中間層の出力を入力に戻す構造となっており、入力層から連続したデータが入ってくる場合に有効です。一見中間層が薄いように見えますが、中間層の出力データが再帰することで、データが入力される度に中間層が厚くなるのと同様の効果を持ちます。RNNは音声認識や機械翻訳といった、自然言語処理の分野で有効なニューラルネットワークの構造です(図5)。
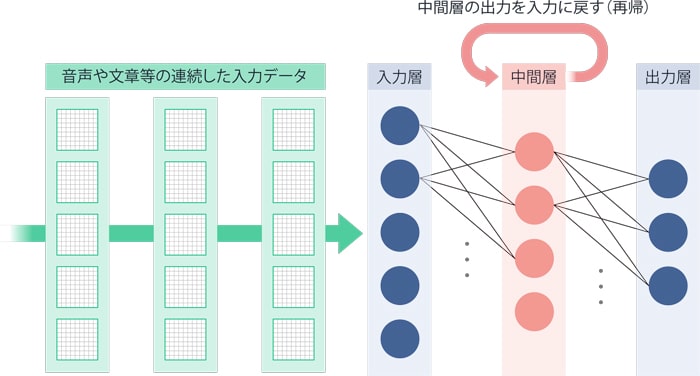 図5:RNN(再起型ニューラルネットワーク)
図5:RNN(再起型ニューラルネットワーク)
AI / ディープラーニングにGPUが使われる理由
ニューラルネットワークを構成するニューロンの演算は同時並列に演算させることができます。このとき、コア数の多いGPU(グラフィクス・プロセッシング・ユニット)を使用することで、多くの演算が並列に処理され高速化できるというわけです。
GPUは元々コンピュータでの3Dグラフィックス描画を高速化させる目的で進化してきました。例えば、3Dグラフィックス上で物体を回転させると、物体の描画点それぞれに回転の演算を行う必要があります。しかしこの場合は、描画点毎に順番に演算するよりも、それぞれの描画点の演算処理を別々に並列演算した方が高速化可能です。
GPUはこの3Dグラフィックスの並列演算のために数百、数千のマルチコア構成になっていました。これがディープラーニングの演算にも有効であったというわけです。
 図6:CPUとGPU
図6:CPUとGPU
ディープラーニングの実運用
産業分野におけるディープラーニングの運用イメージや各プロセスで何を用意したらよいかを説明します。
実際の運用イメージと各プロセスでの考え方
ディープラーニングによって学習されたニューラルネットワークに対象データ(猫の画像)を与えると、その認識の判定結果(「この画像は猫です」)を得ることができます。この実行を推論と言い、学習済みのニューラルネットワークのことを推論モデルと呼びます。逆に言えば、この推論モデルを作る作業が学習ということになります。
学習には多くのデータと演算が必要になりますが、推論の実行には学習時ほどの演算能力は必要ありません。このため、ハイパフォーマンスなコンピュータで学習を行い、その結果として得られた推論モデルを現場のコンピュータ(エッジAIコンピュータ)に実装するというのが実運用の形になります(図7)。
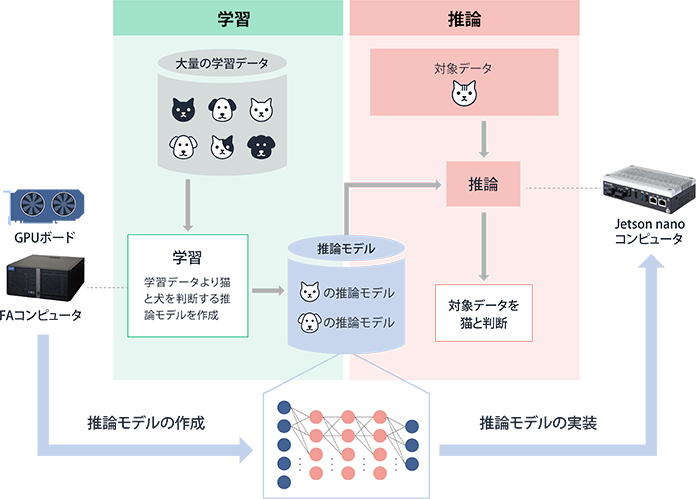 図7:AIアプリケーションの運用イメージ
図7:AIアプリケーションの運用イメージ
産業分野における推論モデルの作成(学習環境)
ディープラーニングにはGPUボードを搭載したハイパフォーマンス・コンピューティング(HPC)環境が必要です。一時的な学習環境であれば、コンシューマ向けのPCやクラウド環境が使われますが、継続的な運用になる産業用途では、製品の信頼性や供給が受けられる期間が課題になります。
高性能なGPUボードが実装できる拡張スロット、大容量電源、またGPUボードの性能を引き出せる高性能CPUを搭載し、製品供給・修理保守サービスが長期に渡って受けられる産業用コンピュータを用意するのが理想的でしょう。
コンテックでは、ハイエンドGPUボード対応の拡張スロット、大容量1000W 電源、大容量RAIDストレージを選択可能な高性能FAコンピュータを用意しています。
産業分野における推論モデルの実装(実行環境)
推論実行環境としてNVIDIA社のJetson開発者キットが有名です。Jetson開発者キットはAIアプリケーションを段階的に始める開発者・教育向けのツールであるため、産業分野では機器としての耐環境性、供給期間、設置性、I/Oインターフェイス不足が課題になることがあります。
コンテックでは、NVIDIA® Jetson Nano™ / Xavier NX™ モジュールを搭載した推論実行用のコンピュータを用意しています。産業用途に向けたGigabit LAN、HDMI、2x USB、汎用I/O、RTC(リアルタイム/カレンダクロック)を搭載、柔軟な設置性と耐環境性を実現しています。

NVIDIA® Jetson Nano™搭載 産業用エッジAIコンピュータ

NVIDIA® Jetson Xavier NX™搭載 産業用エッジAIコンピュータ
AI / ディープラーニングの性能差は何をみればわかる?
ディープラーニングによる推論モデルの作成、推論モデルの実行は、積和演算の並列実行となるため、性能はGPUコアの積和演算能力とコア数に関係します。
演算精度によって異なる積和演算能力(INT8 / FP16 / FP32)
コア内の積和演算精度で、INT8は8ビット整数演算、FP16、FP32は16ビット、32ビットの半精度浮動小数点演算を指します。INT8の項目に1TOPSとあれば、それは1秒間に1兆回の8ビット整数演算ができることを示しています。
推論モデル作成(学習プロセス)では演算精度が重要であるため、半精度浮動小数点演算能力(FP16 / FP32)の性能を重視すべきでしょう。逆に、推論モデル実装(実行プロセス)では演算精度よりも実行速度が重視されるため、整数演算能力(INT8)の性能が重視されます。
とはいえ、ディープラーニングの構造やデータ、GPU以外のシステムによっても結果は変わります。この値だけでディープラーニングの性能を完全に比較することはできません。
ベンチマーク MLPerf / ResNet50 の登場
同じ指標で性能を比較するために業界標準として考え出されたベンチマークがMLPerfです。複数の企業と大学・研究機関などが連携して策定した機械学習ベンチマークで、同じモデルの学習時間、推論時間を計測することで性能を評価します。結果はMLPerfのWebサイトに公開されています。
自分の環境で条件を揃えるならば、特定のモデルの学習、推論時間で比較する方法も有用でしょう。ResNet50は画像認識に用いられる50層のディープラーニングのモデルですが、MLPerfの指標項目の一つでもあり、異なるシステムの性能比較によく用いられます。
コンテックのAI / ディープラーニング向けプラットフォーム
下表はコンテックのAI / ディープラーニング向け製品の一覧です。推論モデルの実装(実行環境、エッジAIコンピュータ)などAIに特化した製品をDXシリーズとして展開しています。また、推論モデルの作成(学習環境)として、高性能 FAコンピュータ VPCシリーズを展開しています。VPCシリーズではGPUボードを実装済で出荷するキッティングサービス(有償)を行っています。
関連コンテンツ
技術コラムTOPへ戻る
技術コラムなどのお役たち情報を含めた最新情報をメルマガでお届けしています。( メルマガサンプル表示 )
)
※
myCONTEC会員にご登録済みで、メルマガ配信をご希望の方は、ログイン後「
会員情報変更」より設定変更ください。