Essential AI Terms: Tips for Keeping Up with Industrial DX
Significant advancements in deep learning technology have ushered in increased practical applications of artificial intelligence (AI) technology in research and development. Expectations are high that such applications will allow for new solutions to various social issues.
In the industrial sector, IoT and 5G communication technologies have allowed for real-time collection of detailed field data. AI technology also allows companies to adapt to changing circumstances quickly. Meanwhile, the opportunities for digital transformation (DX) also increase.
The following blog includes a summary of AI-related technologies and terminology. We have also included examples of industrial AI applications and guidance on how best to prepare for each process.
Relationship between AI and deep learning — Peripheral technologies summary
When most people think of AI, they think of deep learning. However, most people don't fully understand the relationship between these two concepts.
Let’s take a closer look at the relationship between AI and its related peripheral technologies. (Fig. 1)
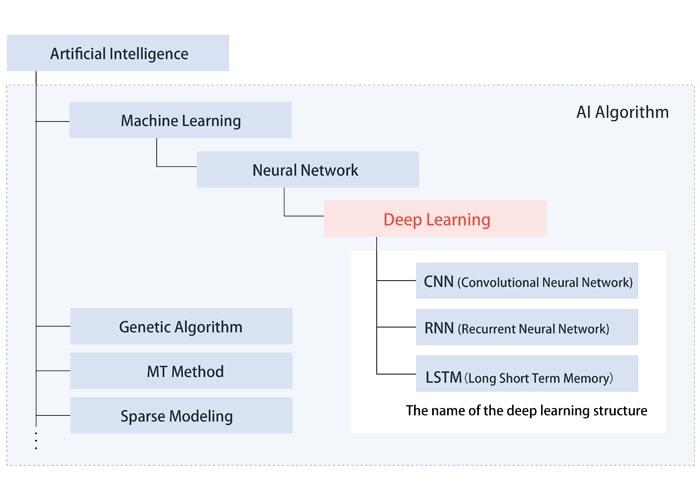 Fig. 1:AI and its related peripheral technologies
Fig. 1:AI and its related peripheral technologies
Deep learning
Deep learning is a machine learning method used in AI algorithms. It can be categorized as the next step in the evolution of the neural network.
Machine learning
As the name suggests, machine learning is an algorithm that allows a machine (computer) to “learn” and make decisions based on gathered data without the need for human programming. To achieve this, neural networks adopt a structure similar to that of human neural circuits. (Fig. 2)
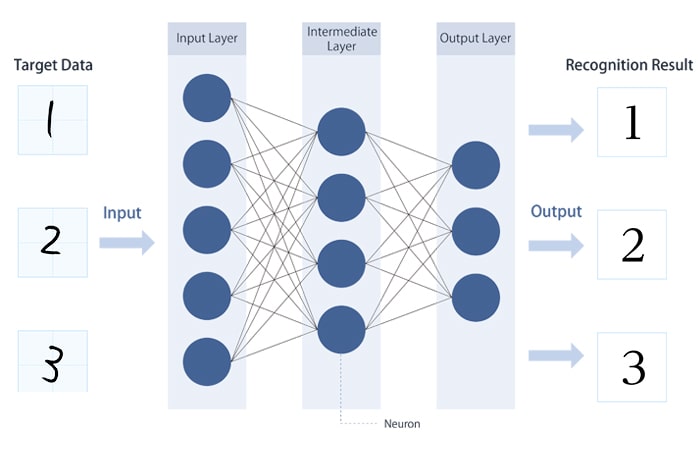 Fig. 2:Image recognition using a neural network
Fig. 2:Image recognition using a neural network
In a neural network, deep learning is the term used for the learning algorithm in the deep, multi-stage intermediate layer structure (deep neural network). (Fig. 3)
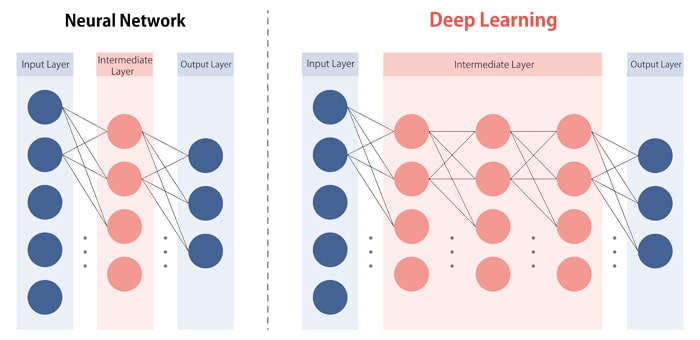 Fig.3: Neural network and deep learning structures
Fig.3: Neural network and deep learning structures
Deep learning can be further divided into two types: Convolutional neural networks (CNN), which are suitable for image recognition, and recurrent neural networks (RNN), which are good for recognizing time-based data such as voice and video.
In its broadest sense, AI includes various other algorithms in addition to machine learning, including genetic algorithms, MT methods, and sparse modeling. These algorithms may be more appropriate for specific applications.
However, deep learning—a type of machine learning—has proven useful for image and speech recognition, triggering today’s third AI boom. This algorithm is also expected to see the most development going forward.
Why are GPUs commonly used for AI and deep learning?
The operations of the neurons that make up a neural network can be performed in parallel, and the large number of cores in a graphics processing unit (GPU) make it possible to perform more parallel operations at once, enabling higher overall speeds.
GPUs were originally developed to speed up 3D graphic rendering on computers. For example, when rotating an object in 3D, the rotation operation must be performed for each of the object’s drawing points. Instead of computing each drawing point one at a time, however, computing each drawing point separately in parallel helps speed up processing of the graphics.
Thus, GPUs were designed with hundreds or even thousands of multicores capable of performing these parallel processes for 3D graphics. The high number of cores also makes GPUs effective for deep learning operations.
 Fig.4:CPU and GPU
Fig.4:CPU and GPU
Example operations and process concepts
By feeding target data (for example, the image of a cat) into a neural network trained with deep learning, we are presented with the recognition judgment results (“This is an image of a cat.”). This recognition is called inference, and the trained neural network is referred to as the inference model. As such, training is the term used for the process of creating this inference model.
Training requires significant amounts of data and computations, but inference requires much less computing power. Actual operation involves training on a high-performance computer and implementing the resulting inference model on a computer in the field (an edge AI computer). (Fig.5)
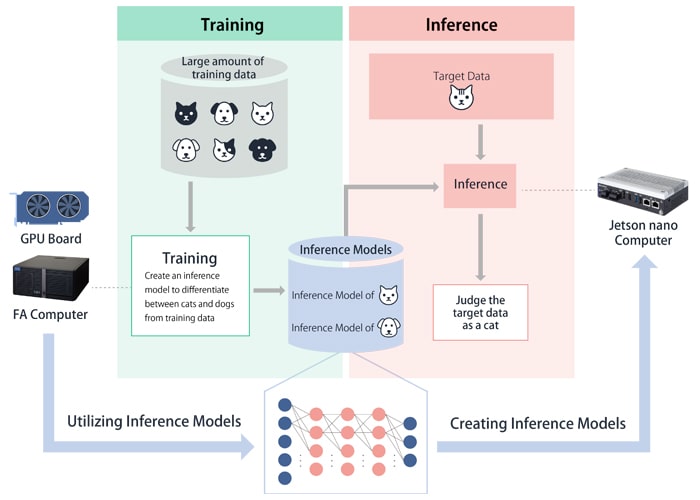 Fig.5:Operational image of AI applications
Fig.5:Operational image of AI applications
Creating inference models for the industrial field (Learning environments)
Deep learning requires a high-performance computing (HPC) environment equipped with a GPU board. Consumer PCs and cloud environments are sufficient for temporary learning environments, but for industrial applications requiring continuous operation, such devices can cause issues in product reliability and supply periods.
The ideal device is generally an industrial computer with expansion slots for adding high-performance GPU boards, a high-capacity power supply, a high-performance CPU that can utilize the high performance of the GPU boards, and extended product availability and repair/maintenance services.
Contec offers high-performance FA computers with a wide selection of expansion slots compatible with high-end GPU boards, high-capacity 1000 W power supplies, and high-capacity RAID storage.
Utilizing inference models in the industrial field (Execution environments)
NVIDIA’s Jetson developer kit is a well-known inference execution environment. However, because the Jetson developer kit is designed for developers just starting to create AI applications, the inferior environmental resistance performance, supply period, installability, and available I/O interfaces can make industrial use challenging.
To solve this, CONTEC offers computers equipped with NVIDIA® Jetson Nano™/Xavier NX™ modules for inference. In addition to flexible installability and advanced environmental resistance, the computers also offer various ports for industrial applications, including Gigabit LAN, HDMI, USB (×2), general-purpose I/O, and RTC (real-time calendar/clock).

Industrial Edge AI Computer with NVIDIA® Jetson Nano™

Industrial Edge AI Computer with NVIDIA® Jetson Xavier NX™
AI and deep learning performance differences
Using deep learning to create and execute inference models allows for parallel execution of product-sum operations, meaning the performance is closely related to the product-sum operation capability of the GPU and the number of GPU cores.
Operational precision and product-sum operating performance(INT8 / FP16 / FP32)
The product-sum operation precision in a core includes INT8 for 8-bit integer operations, and FP16 and FP32 for 16-bit and 32-bit half-precision floating-point operations, respectively. If INT8 core precision is indicated as “1 TOPS,” 1 trillion 8-bit integer operations can be performed every second.
Because computational accuracy is important for creating inference models (learning processes), the half-precision floating-point operation (FP16/FP32) performance is emphasized. On the other hand, speed is more important than operation precision for implementing inference models (execution processes), so the integer operation (INT8) performance is emphasized.
However, the results will vary depending on the deep learning structure, the data, and the system components besides the GPU. As such, this value alone is insufficient for determining deep learning performance.
Introducing MLPerf/ResNet50 benchmarks
MLPerf benchmarks were devised as industry standards to compare performances using the same metric. Developed in collaboration with multiple companies, universities and research institutes, and other entities, these machine learning benchmarks evaluate performance by measuring the training and inference times between similar models. Results are made available on the MLPerf website.
However, comparing the training and inference times for a particular model under the environmental conditions that will be used can also be useful. ResNet50, a 50-layer deep learning model used for image recognition, is one MLPerf metric item and is often used to compare the performance of different systems.
Contec’s AI/deep learning platform
The following table lists all of CONTEC’s AI and deep learning products. CONTEC is developing products such as the DX Series with a strong focus on AI, including inference model implementation (execution environments, edge AI computers). We are also utilizing the VPC Series of high-performance FA computers to create inference models (learning environments). A kitting service (fee required) is also available for the VPC Series and includes pre-installed GPU boards.
-
*
The manufacturer’s nominal value is indicated for INT8, FP16, and FP32, if available. If no manufacturer nominal value is available, the TechPowerUp! value is indicated.
Related Links
See All Blogs
*
If you have already registered as a myCONTEC member and wish to receive eNewsletters, please change the settings from
"Edit Profile" after logging in.